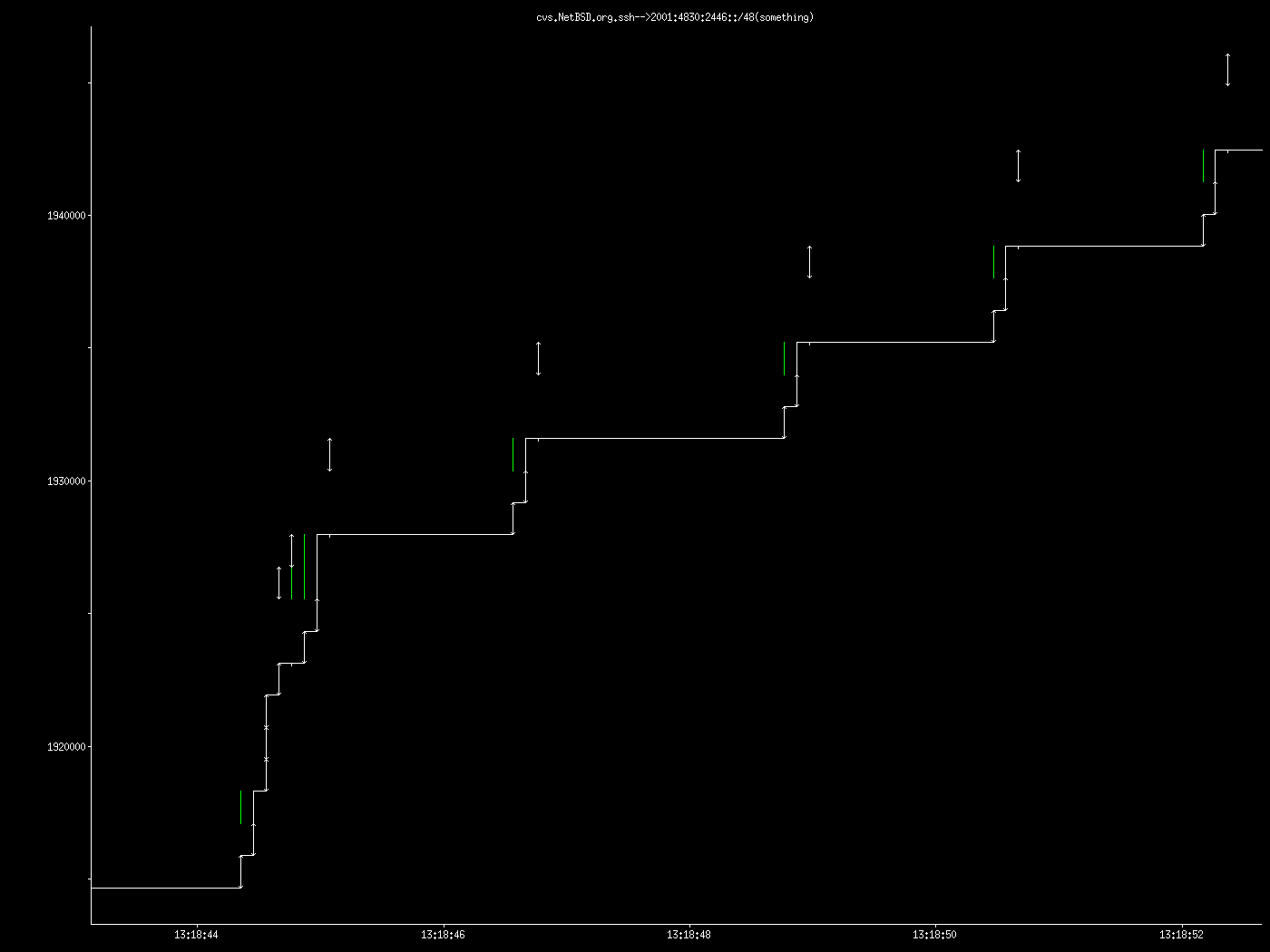
I have systems at BBN and at MIT set up for IPv6. The provider at BBN is sixxs.net, and at MIT OCCAID. I did a cvs update -r netbsd-5 of a netbsd-4 tree, and it took forever, as in went nearly 24h and didn't finish. I ran tcpdump and found very strange sack behavior. With IPv4 I don't get the odd behavior, and from BBN I don't get strange behavior, although when grabbing pkgsrc.tar.gz I get only 275 KB/s with v6 instead of 700 KB/s with v4. From MIT I get 760 KB/s with v4 and with v6 about 800 B/s (yes, 800 bytes per second). A partial traceroute to ftp.netbsd.org from my MIT machine: 1 2001:4830:2446:3e::1 0.29 ms 0.264 ms 0.258 ms 2 limekiller.ipv6.mit.edu 0.826 ms 0.821 ms 0.849 ms 3 bbr01-tu100.bstn01.occaid.net 1.804 ms 1.993 ms 1.922 ms 4 bbr01-g1-0.chcg01.occaid.net 28.466 ms 28.546 ms 28.483 ms 5 bbr01-p2-1.kscy01.occaid.net 41.833 ms 41.476 ms 41.79 ms 6 bbr01-p1-0.snfc02.occaid.net 77.68 ms 77.736 ms 77.61 ms 7 2001:4f8:4:b::1 78.043 ms 77.717 ms 77.774 ms 8 sfo2-sql1.r1.sql1.isc.org 78.787 ms 78.344 ms 78.784 ms Looking at the tcpdump, it seems sometimes one segment arrives every 3 seconds or so, very reguarly (not shown in graph). Then, there's a mode where there are two missing segments (meaning A and D have been received, but not B and C). B is apparently retransmitted, which provokes a SACK showing C missing, and then C arrives, resulting in a full ack for D. Then, for reasons that I can't fathom, G arrives, with E and F missing, and this repeats, staying in this mode indefinitely. I am guessing that with the occaid connection that perhaps there is some very small queue somewhere with tail drop. This graph was produced with tcpdump2xplot from pkgsrc/math/xplot (with a == changed to eq in the test for "IP"). Is anyone else seeing poor IPv6 TCP performance?
Attachment:
xplot-sack.png
Description: PNG image
Attachment:
pgpK9048UHKOl.pgp
Description: PGP signature
{kind=link}